Hyrax Hello World#
This example walks through a small end-to-end Hyrax workflow using a built-in convolutional neural network. This page uses CIFAR10 data rather than astronomy data so that the basic Hyrax workflow is easier to see and understand. The example is based in part on the PyTorch CIFAR10 tutorial and uses the CIFAR10 dataset described in Learning multiple layers of features from tiny images, Alex Krizhevsky, 2009.
Note
In Hyrax, the basic pattern is to first create a Hyrax object, configure a
model and a data_request, and then run verbs such as
train and infer.
This example will:
Create a Hyrax instance
Specify a model and a dataset
Train the model
Predict with the model
Evaluate the results
You can also run this example in Google Colab:
![]()
Create a Hyrax instance#
The main driver for Hyrax is the Hyrax class. To get started we’ll create
an instance of this class.
from hyrax import Hyrax
h = Hyrax()
When we create the Hyrax instance, it automatically loads a default
configuration file containing baseline settings for the components Hyrax uses.
In this example, we will update configuration values directly in Python with
h.set_config(...), but configuration can also be supplied in an external
TOML file with entries such as model.name = "HyraxCNN". You can read more
about this in the configuration system.
Specify a model#
We’ll need to let Hyrax know which model to use for training. Here we’ll tell Hyrax to use the built-in HyraxCNN model that is based on the simple CNN architecture from the PyTorch CIFAR10 tutorial.
h.set_config('model.name', 'HyraxCNN')
In Hyrax terms, specifying the model is one of the required inputs for a run.
You do not need to use a built-in model. Hyrax also supports defining custom models.
Define the dataset#
We’ll also need to tell Hyrax what data should be used for training, in this case the CIFAR10 dataset.
Hyrax has a built-in dataset class for working with CIFAR10 data, so we’ll configure that here. You can learn more about CIFAR10 at the official site: https://www.cs.toronto.edu/~kriz/cifar.html
1data_request_definition = {
2 "train": {
3 "data": {
4 "dataset_class": "HyraxCifarDataset",
5 "data_location": "./data",
6 "fields": ["image", "label"],
7 "primary_id_field": "object_id",
8 "split_fraction": 1.0,
9 },
10 }
11 }
12
13 h.set_config("data_request", data_request_definition)
This may appear overwhelming, especially for a simple case, but being explicit
about the dataset configuration will allow for greater flexibility when working
with more complex data. In Hyrax, the data_request defines what data each
stage of the workflow should use.
Hyrax also includes built-in datasets for several astronomy workflows, and users can define custom dataset classes when needed.
Train the model#
Now that we have the model and data specified, we’re ready for training. We’ll
use the train verb to kick off the training process.
h.train()
Once the training is complete, the model weights will be saved in a timestamped
directory with a name similar to /YYYYmmdd-HHMMSS-train-RAND. Note that
RAND is a random four character string to avoid collisions if you run
multiple training sessions in the same second.
Predict with the model#
Now that we’ve trained a model, we can use it to infer classes of samples from the CIFAR10 test dataset. This follows the same pattern as training: first update the configuration, then run the next verb.
First we’ll add to our model input definition to specify the data to use for inference.
1data_request_definition["infer"] = {
2 "data": {
3 "dataset_class": "HyraxCifarDataset",
4 "data_location": "./data",
5 "fields": ["image"],
6 "primary_id_field": "object_id",
7 "dataset_config": {
8 "HyraxCifarDataset": {
9 "use_training_data": False,
10 },
11 },
12 },
13}
14
15h.set_config("data_request", data_request_definition)
Then we’ll use Hyrax’s infer verb to load the trained model weights and
process the data defined above.
inference_results = h.infer()
Evaluate the performance#
Let’s compare the model’s predictions to the actual labels from the test
dataset. The model’s prediction is a 10 element vector where the largest value
represents the highest confidence class. So we’ll extract the index of the max
value for each prediction and save that as predicted_classes. We’ll also
load the original test data to get the true labels for comparison.
1import numpy as np
2import pickle
3
4# Accumulate the predicted classes
5predicted_classes = np.zeros(len(inference_results)).astype(int)
6for i, result in enumerate(inference_results):
7 predicted_classes[i] = np.argmax(result)
8
9# Load the true labels
10with open("./data/cifar-10-batches-py/test_batch", "rb") as f_in:
11 test_data = pickle.load(f_in, encoding="bytes")
Using scikit-learn’s confusion_matrix, we can compute and display the
confusion matrix to see how well the model performed on each class.
1import matplotlib.pyplot as plt
2from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
3
4y_true = test_data[b"labels"]
5y_pred = predicted_classes.tolist()
6
7correct = 0
8for t, p in zip(y_true, y_pred):
9 correct += t == p
10
11print("\nAccuracy for test dataset:", correct / len(y_true))
12
13cm = confusion_matrix(y_true, y_pred)
14disp = ConfusionMatrixDisplay(confusion_matrix=cm)
15disp.plot()
16plt.show()
>> Accuracy for test dataset: 0.5003
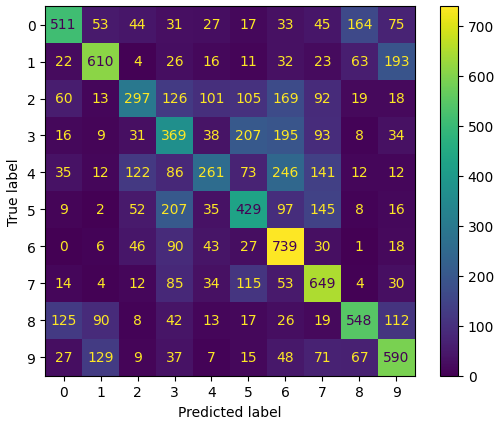
The model performs much better than chance (which would be 10%) with some classes being predicted more accurately.#
What to Take Away
A Hyrax workflow starts by configuring a
Hyraxobject, which can be configured using a configuration file or updated directly in Python.The model and the
data_requestare configured separately and are both required inputs to the workflow.Verbs such as
trainandinferrun the configured workflow.