Checkpoint with Hyrax#
This notebook demonstrates how to save and resume models with checkpointing in Hyrax.
[1]:
# setup
from hyrax import Hyrax
from hyrax.config_utils import find_most_recent_results_dir
Checkpoint Generation#
Hyrax automatically creates a checkpoint file in the results directory of a training run after each epoch. Each training run has a directory that begins with the timestamp of that run and inside that directory is a .pt file that begins with checkpoint_epoch_; the number following that is the last completed epoch for this checkpoint. When an epoch finishes, the checkpoint for that epoch overwrites the previous checkpoint. For example, the model below will generate
checkpoint_epoch_5.pt if training finishes completely, but it generates checkpoint_epoch_{i}.pt for i from 1 to 4 along the way.
Hyrax also creates a checkpoint at the end of the epoch where the model produces the lowest loss value.
We’ll reuse the same config from Getting Started, stored in a file:
[model]
name = "HyraxCNN"
[data_request.train.data]
dataset_class = "HyraxCifarDataset"
data_location = "./data"
fields = ["image", "label"]
primary_id_field = "object_id"
split_fraction = 1.0
[data_request.infer.data]
dataset_class = "HyraxCifarDataset"
data_location = "./data"
fields = ["image", "object_id"]
primary_id_field = "object_id"
[data_request.infer.data.dataset_config.HyraxCifarDataset]
use_training_data = false
[ ]:
h = Hyrax(config_file="./getting_started_config.toml")
h.set_config("model.name", "HyraxCNN")
h.set_config("train.epochs", 5)
trained_model = h.train()
Loading Checkpoints#
Checkpoints can be loaded to resume training from the checkpointed state of the model. The only step to do this is to set the resume config to point to the checkpoint file:
[ ]:
checkpoint_filename = "checkpoint_epoch_5.pt"
results_dir = find_most_recent_results_dir(h.config, "train")
checkpoint_path = results_dir / checkpoint_filename
h.set_config("train.resume", str(checkpoint_path))
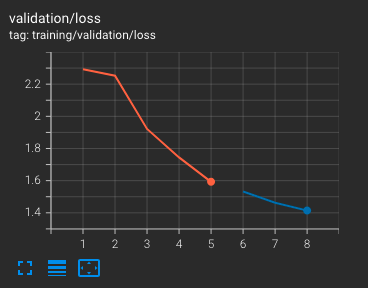
If we update the number of epochs to 8, then the model will resume training for 3 more epochs.
[ ]:
h.set_config("train.epochs", 8)
trained_model = h.train()
The resumed training data will create its own timestamped results directory with new checkpoints and will not overwrite the previous one. Note that if a model that should run for n epochs finishes its training and the checkpoint is loaded with the number of epochs still being n, then the model will be trained for n more epochs.
Additional training from a checkpoint can be seen in TensorBoard as well; the validation loss is plotted against each epoch and the red curve represents the validation loss from the initial training while the blue curve is the validation loss from the additional 3 epochs.